حمله DHCP Spoofing چیست؟ و راهکار DHCP Snooping برای مقابله با آن
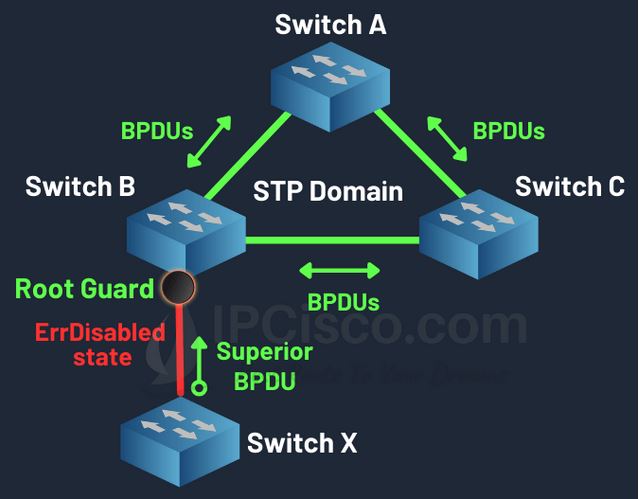
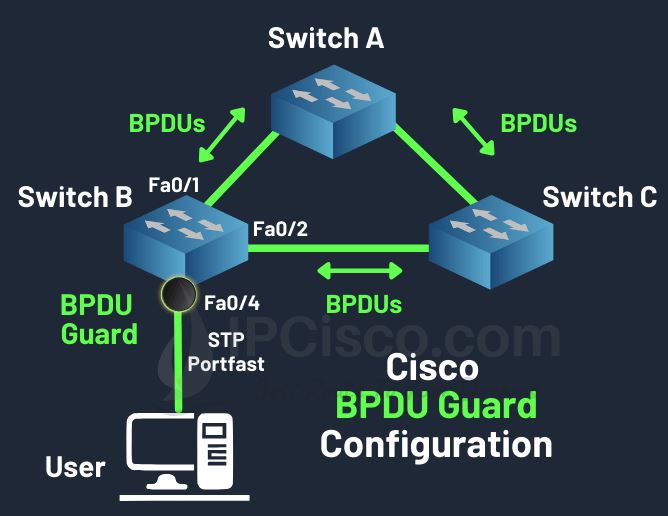
DHCP Spoofing حمله ای است که عملکرد سرویس DHCP (اختصاص IP به صورت اتومات) را مختل می کند. این حمله به دو صورت می تواند به وجود اید: برای جلوگیری از این حملات از DHCP Snooping استفاده می کنیم و به صورت زیر عمل می کند :برای جلوگیری از حالت اول پورتی که متصل به DHCP سرور ماست را […]